

티스토리 뷰
드디어 걱정하든 단원까지 오게 되었다.. 이 단원부터 알고리즘의 시작이라고 할 수 있겠다. 물론 아직 쉬운 단계일지 몰라도 이를 알면서 좀 더 실생활적인 문제를 풀어나갈 수 있기 때문이다. 오늘은 1차원 배열을 위주로 살펴보려고 한다.
여기서 한단계 바로앞에 이차원 배열이 나오게 될텐데, 큰 기점이 될 기준이라고 생각한다. (이미 2차원 배열을 배우고 있으면서 너무 힘들었기 때문..)
그래도 힘내서 해보자.
배열
: 일정한 자료형의 변수들을 하나의 이름으로 재할당하여 사용하는 자료데이터
: 일일이 다른 변수명을 이용해 자료에 접근하는 것은 매우 비효율적이다.
: 아래의 그림처럼 여러 변수를 배열을 통해 통합한다음 다양한 작업을 할 수 있다.

1차원 배열
1차원 배열의 선언
: 별도의 선언 방법을 필요로 하지 않는다면 빈 배열을 생성한다 (앞서 list를 다룰 때 많이 봤을 것이다)
1차원 배열의 접근
: 배열을 만들었다면 해당하는 데이터에 접근하는 방법도 알아야 한다. 또한 list로 생성된 데이터들은 앞서 배웠듯 Sequence에 iterable(반복가능), mutable(가변) 데이터라 기본이된다고 말한적이 있다. 어떻게 접근하는지 살펴보자
해당 배열에 접근하기 위해서는 인덱스를 사용하며, 일반 변수를 할당하는 것처럼 인덱스 접근 후 데이터 할당한다고 생각하면 된다. 예시를보면 접근전에 데이터와 접근 후 할당한 데이터 전체 출력을 보면 바뀌어 있는 것을 확인 할 수 있다.
정렬
: 2개 이상의 자료를 특정 기준을 통해 오름차순(Ascending) or 내림차순(Descending)으로 재배열 하는 것을 의미한다.
예를들면 요즘 많이 즐겨하는 보드게임중에 루미큐브를 생각 할 수 있겠다. 루미큐브를 처음 패를 받게되면 같은 숫자를 모아두거나 숫자가 커지도록 정렬하는 사람들이 대부분일 것이다. 혹은 카드게임을 할 때, 금액 등 오름차순으로 정렬하는 모습을 실생활에서도 흔하게 볼 수 있다.

그렇다면 정렬 방식에는 어떤 것이 있을까?
버블 정렬, 카운팅 정렬, 선택 정렬, 퀵 정렬, 삽입 정렬, 병합 정렬
위의 정렬들이 대표적이라고 볼 수 있다. 하나씩 살펴보자. (근데 이거 CT문제에서 본거같은데~)
버블 정렬(Bubble Sort)
: 인접한 두개의 원소를 비교해서 정렬하기 위한 형태로 자리를 연속적으로 교환하는 방식
: 교환하면서 자리를 이동하는 모습이 물 위에 올라오는 거품모양과 유사하다 하여 버블 정렬이라고 한다.
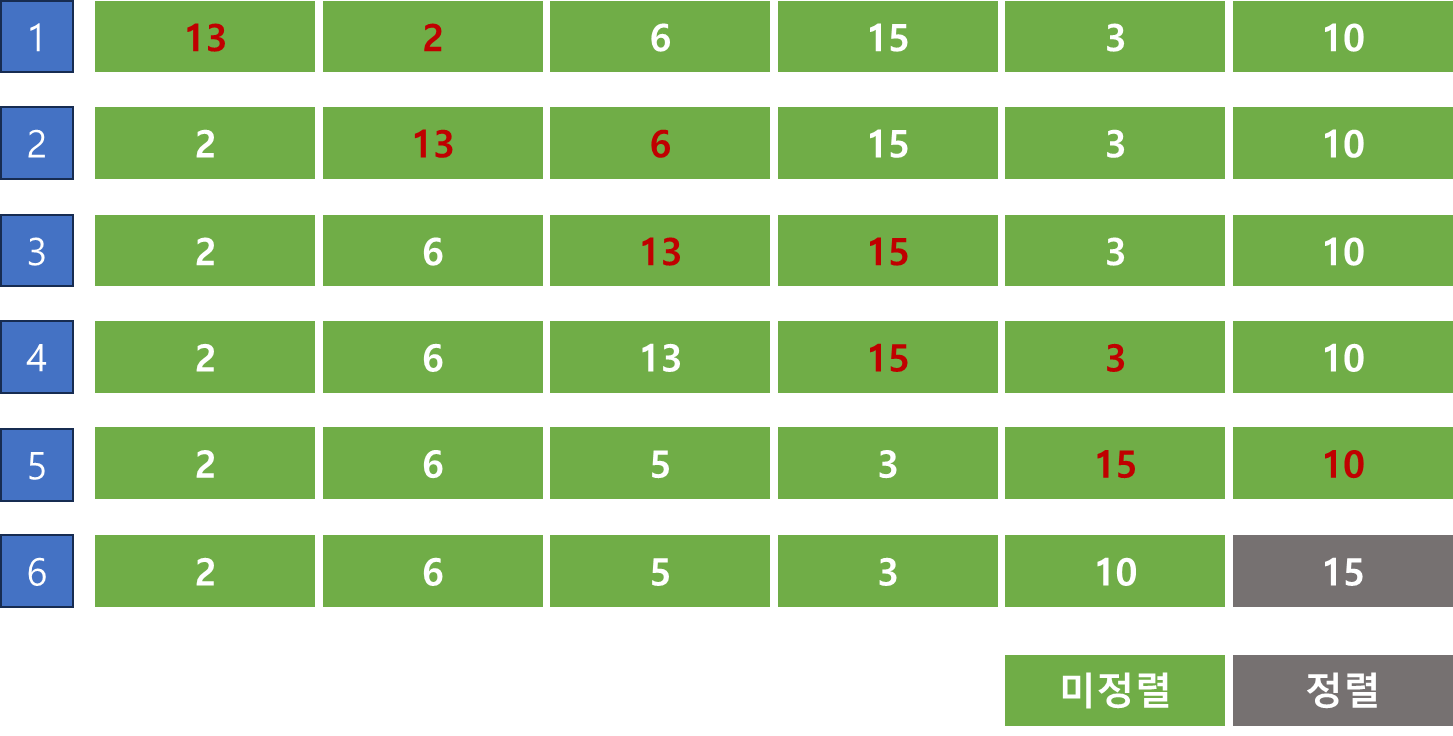
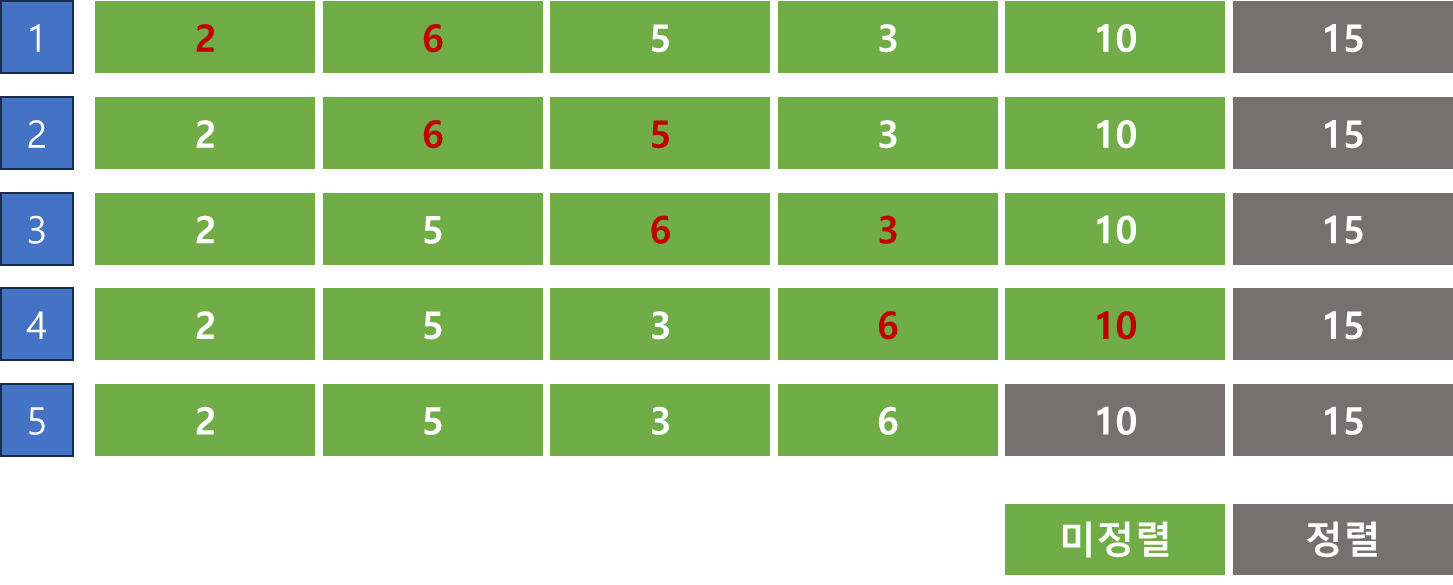
- 가장 왼쪽의 첫번째 원소부터 인접한 원소끼리 계속 자리를 교환하며 마지막 자리까지 이동한다.
- 한 단계가 끝났을 때, 가장 큰 원소가 마지막 자리로 정렬된다.
- 시간 복잡도 O(n**2)
- 가장 앞에서 시작하지만, 해당 원소를 위치잡아주는 것이 아닌 가장 우측 데이터를 고정하는 것이다.
아래는 리스트 [13, 2, 6, 15, 3, 10]을 버블정렬하는 과정을 보여준다.




위의 과정을 코드로 작성해보자.
이해하는데 시간이 오래 걸렸던 부분은 i의 range를 N-1부터 0까지 -1만큼 반복하는 과정을 이해하기가 어려웠다. 해석하자면 간단하다. 맨 처음 가장 왼쪽 데이터 두개를 비교하면서 넘어갈때, 5번 버블 정렬 하는 것을 위에서 봤을 것이다. 그 이후 정렬 되었다면 4번 버블, 3번버블 ... 1번버블로 될 것이다. 이를 보여주기 위해 range(N - 1, 0, -1)이며, 버블 정렬 된 횟수에 따라 j의 범위가 정해지므로 해당 범위 N-1을 i로 받아준다. 이후 데이터를 비교해 오른쪽으로 이동하는 것이라고 해석할 수 있다.
카운팅 정렬(Counting Sort)
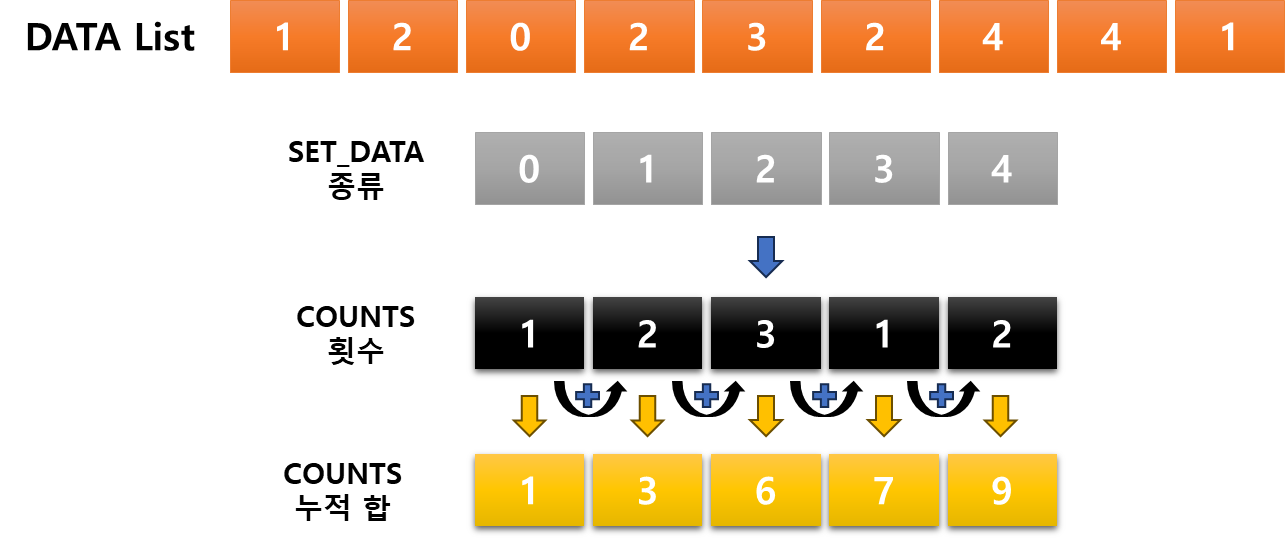
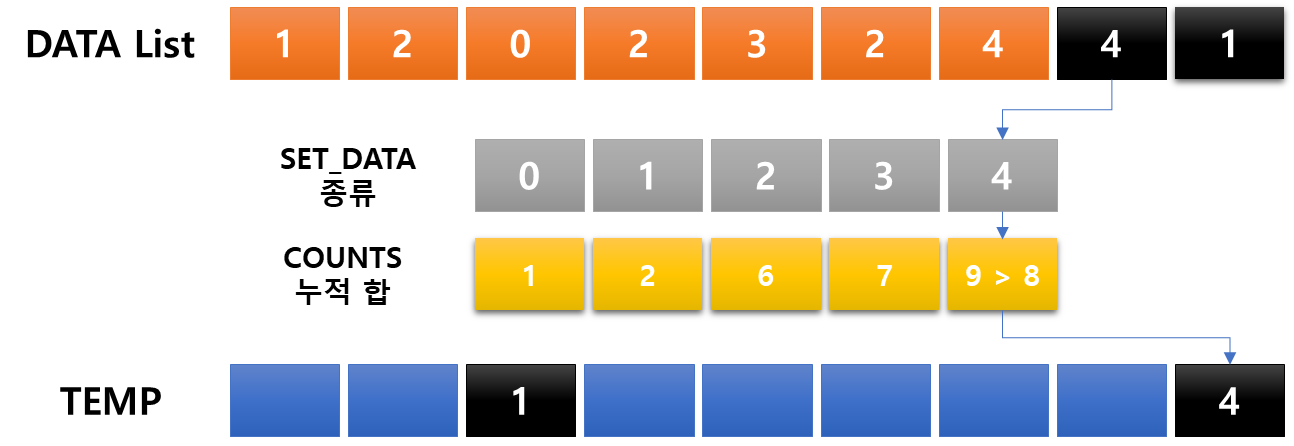
: 항목들의 순서를 결정하기 위해 데이터들의 집합에 각 데이터들이 몇 개씩 있는지 '세는 작업'을 하여 효율적이고 간편한 정렬 알고리즘
- 제한 사항 : 정수 혹은 정수로 표현할 수 있는 데이터에 한에서만 사용이 가능하다. 각 항목의 카운트 횟수를 기록하기 위해 정수 데이터로 인덱스 되는 카운트들의 배열을 사용 때문
- 충분한 공간을 할당하려면 데이터 집합 내에 가장 큰 정수를 알아야 한다.
- 시간 복잡도 : O(n + k) *n=리스트 길이, k는 정수의 최댓값



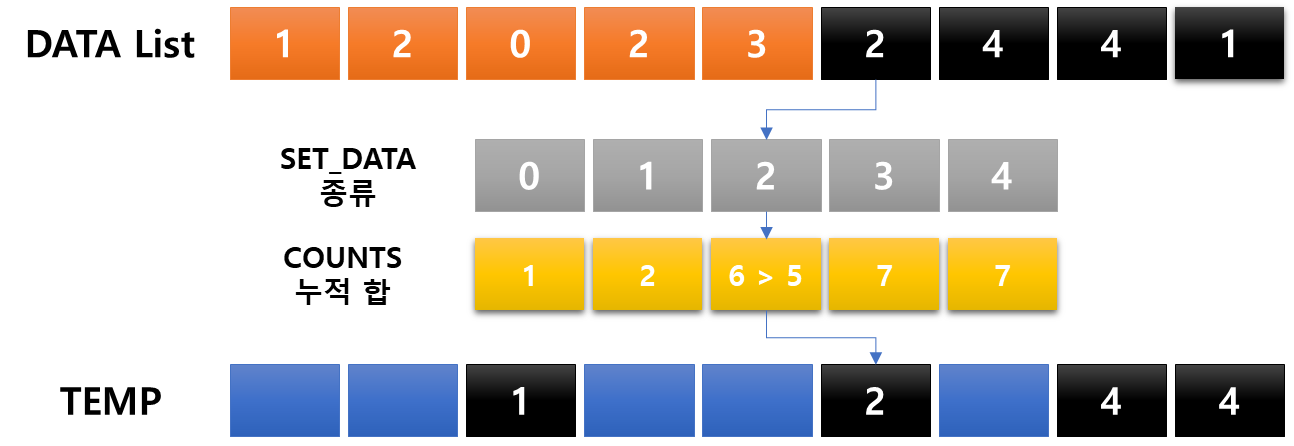

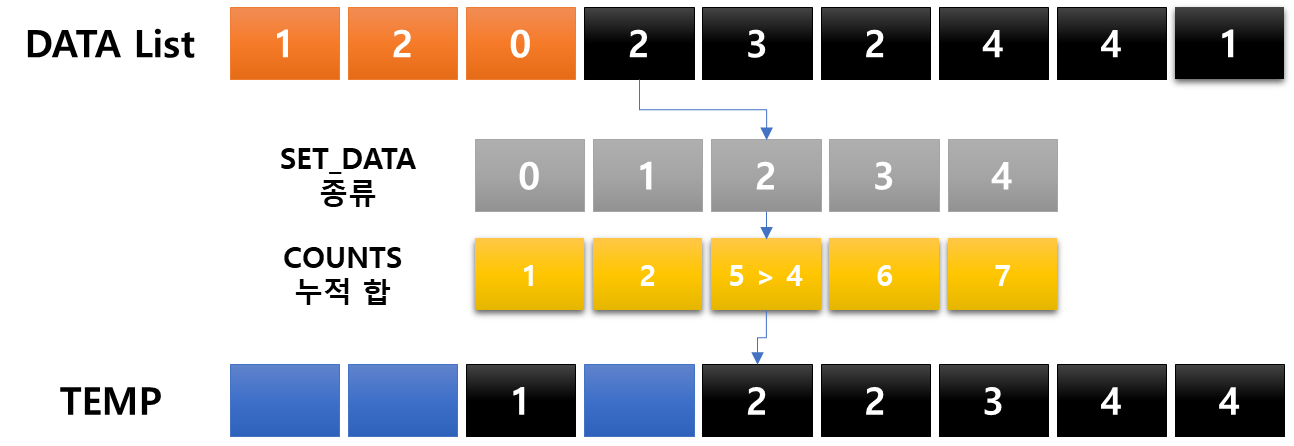
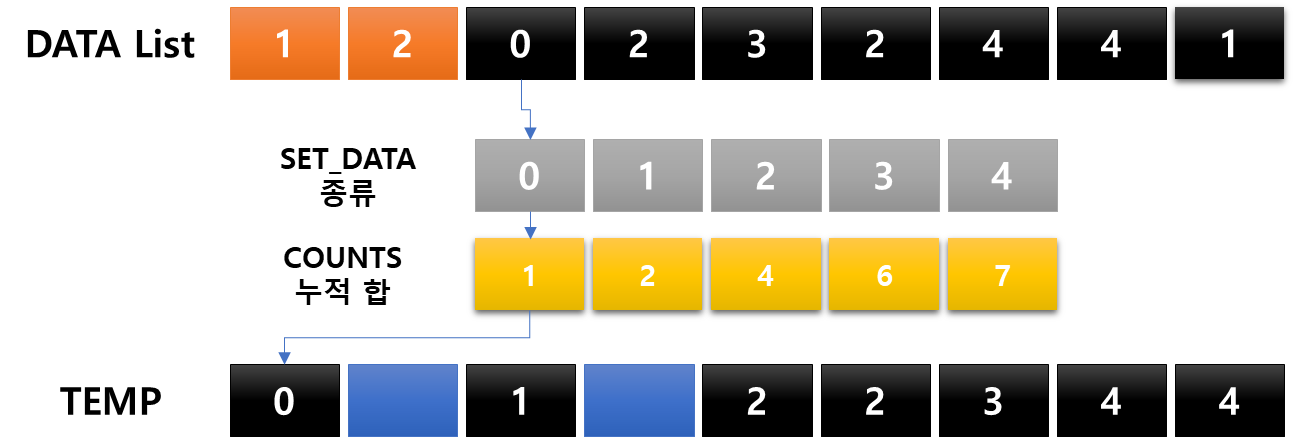


코드로도 살펴보자.
굉장한 작업도 아닌데, 굉장해보인다. 다만 왜 일일이 다 해봤냐면, 어떤 메커니즘으로 이루어지는지 궁금했고 직접 정리하는 과정에서 기억을 하려했다. 예를들어 누적합을 구해놓고 어떻게 카운팅 되는지, 왜 해당 위치에 들어가게 되는지 정확하게 알고 싶었다. 교육자료처럼 만든다면 기억이 더 잘 되지 않을까?
일단 기본적인 데이터의 정보를 알고있어야 사용이 가능한 sort 함수인 것 같다. 함수에 넣기 전에 arr과 temp, k 모두를 설정하는 과정에서 머리가 터질뻔했다. 내가 생각하는 함수의 형태는 인자를 넣었을 때 출력되는 것인데, 이 함수는 초기 설정이 필요하다고 생각한다. 초기 코드에서 gpt의 힘을 빌려 수정을 하긴 했는데.. 아직은 정확히 이해되지 않았다. 알게된다면 추가 수정을 하려한다.
'일상코딩 > 노트' 카테고리의 다른 글
| Python : Stack (1) (2) | 2024.02.07 |
|---|---|
| Python : 완전 탐색과 그리디 알고리즘 (Baby-gin) (1) | 2024.02.01 |
| Python Functions(2) [재귀함수, 유용한 내장함수] (1) | 2024.01.27 |
| Python Method (딕셔너리 Method) (0) | 2024.01.26 |
| Python Method (세트 Method) (1) | 2024.01.24 |
- Total
- Today
- Yesterday
- 백준
- ChatGPT
- vue3
- SQLite
- Database
- 순열
- HTML
- basic syntax
- 함수
- Authentication System
- Method
- Sequence types
- Django
- ssafy
- refactoring
- 카운팅정렬
- 삼성청년SW아카데미
- Python
- Component
- dfs
- 연산자
- baby-gin
- SQL
- app
- JavaScript
- CodeTree
- views.py
- vue
- 재귀
- honeymoney
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |